



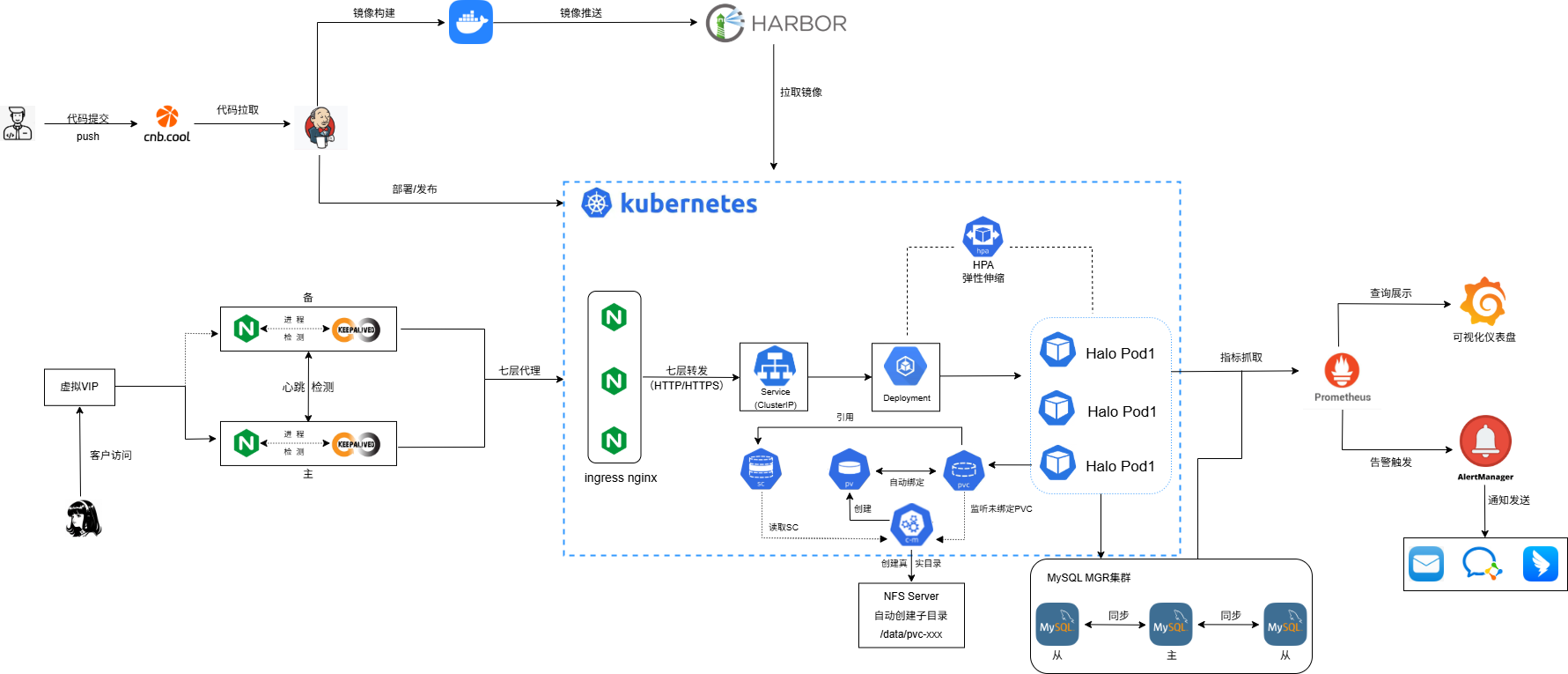
docker
日志轮转
im /etc/docker/daemon.json
{
"registry-mirrors": ["https://docker.1ms.run"],
"insecure-registries":["192.168.135.152"],
"log-driver":
"json-file",
"log-opts":{
"max-size": "10m",
"max-file": "3"
}
}镜像制作
工具镜像
FROM 192.168.135.152/talo/rocky:9.6
WORKDIR /talo
RUN dnf install -y vim wget java-21-openjdk-devel git tar gzip unzip findutils which libatomic.so.1 libatomic xz &&\
wget https://nodejs.org/dist/v26.2.0/node-v26.2.0-linux-x64.tar.xz &&\
tar -xf node-v26.2.0-linux-x64.tar.xz -C /usr/local/ &&\
rm -f node-v26.2.0-linux-x64.tar.xz &&\
dnf clean all && rm -rf /var/cache/dnf /var/cache/yum /tmp/* /var/tmp/*
ENV PATH=$PATH:/usr/local/node-v26.2.0-linux-x64/bin
RUN npm install -g pnpm && npm cache clean --force
CMD ["/bin/bash"]应用镜像
FROM eclipse-temurin:21-jre AS builder
WORKDIR /application
ARG JAR_FILE=/application/build/libs/*.jar
COPY ${JAR_FILE} application.jar
RUN java -Djarmode=tools -jar application.jar extract --layers --destination extracted
FROM eclipse-temurin:21-jre
LABEL maintainer="johnniang <johnniang@foxmail.com>"
WORKDIR /application
COPY --from=builder /application/extracted/dependencies/ ./
COPY --from=builder /application/extracted/spring-boot-loader/ ./
COPY --from=builder /application/extracted/snapshot-dependencies/ ./
COPY --from=builder /application/extracted/application/ ./
ENV JVM_OPTS="" \
HALO_WORK_DIR="/root/.halo2" \
SPRING_CONFIG_LOCATION="optional:classpath:/;optional:file:/root/.halo2/" \
TZ=Asia/Shanghai
RUN ln -sf /usr/share/zoneinfo/$TZ /etc/localtime \
&& echo $TZ > /etc/timezone
RUN java -XX:ArchiveClassesAtExit=application.jsa -Dspring.context.exit=onRefresh -jar application.jar --halo.work-dir=/tmp/halo2 \
&& rm -rf /tmp/halo2
EXPOSE 8090
ENTRYPOINT ["sh", "-c", "exec java ${JVM_OPTS} -XX:SharedArchiveFile=application.jsa -jar application.jar \"$@\"", "--"]部署Harbor私有镜像仓库
Docker的镜像可以借助扫描器来完成镜像的漏洞扫描
#拉取harbor的安装包
[root@www ~]# mkdir /harbor
[root@www ~]# cd /harbor/
[root@www harbor]# wget https://github.com/goharbor/harbor/releases/download/v2.14.0/harbor-offline-installer-v2.14.0.tgz
#证书生成
看上面部署docker官方私有镜像仓库的示例
#修改文件配置
[root@www harbor]# vim harbor.yml
hostname: 192.168.135.152
harbor_admin_password: Harbor12345 #设置admin的密码
https:
port: 443
certificate: /pem/certs/www.zgs.com.pem #证书
private_key: /pem/certs/www.zgs.com-key.pem #私钥
#运行shell脚本
[root@www harbor]# ./install.sh #不安装漏洞扫描工具
[root@www harbor]# ./install.sh --with-trivy #安装漏洞扫描工具
和harbor集成后,可以实现上传镜像到仓库,自动扫描;对于高风险的镜像自动阻止分发和用户拉取
#######################
#这个漏洞扫描的工具也可以单独安装进行使用
[root@www mnt]# wget https://github.com/aquasecurity/trivy/releases/download/v0.67.2/trivy_0.67.2_Linux-64bit.rpm
[root@www mnt]# rpm -ivh trivy_0.67.2_Linux-64bit.rpm
#扫描镜像
[root@www mnt]# trivy image httpd:latest[root@www harbor]# vim harbor.yml #默认不需要修改
trivy:
enabled: true # 是否启用 Trivy 扫描功能,必须开启才能扫描
ignore_unfixed: false #是否忽略未修复的漏洞,false会显示所有漏洞
skip_update: false #是否跳过漏洞数据库的自动更新,false表示启动时更新
skip_java_db_update: false #是否跳过java依赖数据库的更新,false表示更新
offline_scan: false #是否离线扫描(不联网拉取漏洞库),false表示联网更新
security_check: vuln #安全检查类型,vuln表示漏洞扫描;config表示配置检查;all表示全部
insecure: false #是否允许访问不受信任(自签名)https仓库,使用自签证书时设为true
timeout: 5m0s #超时时间
github_token: xxx #GitHub令牌,提高漏洞库拉取速率,留空则使用匿名访问注意
自建的镜像仓库因为https的证书是自生成的,因此需要忽略docker的仓库风险提示,也就是启用不受信任的仓库,要配置docker的daemon.json,并重启docker服务
[root@www conf.d]# vim /etc/docker/daemon.json
{
"registry-mirrors": [
"https://docker.1ms.run"
],
"insecure-registries": [
"192.168.135.152"
]
}暴露Docker API端口
vim /usr/lib/systemd/system/docker.service
ExecStart=/usr/bin/dockerd -H fd:// -H tcp://0.0.0.0:2375 --containerd=/run/containerd/containerd.sock
#添加-H tcp://0.0.0.0:2375,2375是非认证的URL,不需要证书验证的,配置简便。如果需要高安全性则需要使用到TLS证书验证,开放2376端口
#开启TLS证书验证的方式
#生成CA私钥
openssl genrsa -out ca-key.pem 4096
#生成CA自签名证书(有效期10年)
openssl req -new -x509 -days 3650 -sha256 -key ca-key.pem -out ca.pem -subj "/CN=docker-ca"
#生成服务端私钥
openssl genrsa -out server-key.pem 4096
#生成服务端CSR,并直接写入SAN(把示例IP/域名替换成真实值)
openssl req -new -key server-key.pem -out server.csr -subj "/CN=docker-server" -addext "subjectAltName=IP:192.168.135.30" #-addext subjectAltName=... 证书必须包含你连接时用的地址,否则会报x509不匹配
#用CA签发服务端证书,标记用途为serverAuth,并保留CSR里的SAN扩展
printf "subjectAltName=IP:192.168.135.30\nextendedKeyUsage=serverAuth\n" | openssl x509 -req -in server.csr -CA ca.pem -CAkey ca-key.pem -CAcreateserial -out server-cert.pem -days 3650 -sha256 -extfile /dev/stdin
#生成客户端私钥
openssl genrsa -out key.pem 4096
#生成客户端CSR
openssl req -new -key key.pem -out client.csr -subj "/CN=docker-client"
#用CA签发客户端证书,标记用途为clientAuth
printf "extendedKeyUsage=clientAuth\n" | openssl x509 -req -in client.csr -CA ca.pem -CAkey ca-key.pem -CAcreateserial -out cert.pem -days 3650 -sha256 #extendedKeyUsage=clientAuth声明该证书用于TLS客户端认证(dockerd -tlsverify会校验
#修改docker套接字文件
vim /usr/lib/systemd/system/docker.service
ExecStart=/usr/bin/dockerd \
-H unix:///var/run/docker.sock \
--containerd=/run/containerd/containerd.sock \
-H tcp://0.0.0.0:2376 \
--tlsverify \
--tlscacert=/certs/ca.pem \
--tlscert=/certs/server-cert.pem \
--tlskey=/certs/server-key.pem
#客户端连接方式
#客户端家目录下创建.docker隐藏文件
mkdir /root/.docker
#拷贝证书、密钥..
scp key.pem cert.pem ca.pem 192.168.135.20:/root/.docker/
注意:权限设置为400或者600
#使用tls校验进行连接
docker --tls -H tcp://192.168.135.30:2376 ps
#通过定义全局变量实现
export DOCKER_HOST=tcp://192.168.135.30:2376
export DOCKER_TLS_VERIFY=1 #启用TLS认证
export DOCKER_CERT_PATH=/opt #指定认证证书存放的目录
注意:.docker是默认的存放目录,不需要指定kubernetes
配置私有仓库镜像拉取
#创建目录
mkdir /etc/containerd/certs.d/192.168.135.152
#添加配置
vim hosts.toml
server = "https://192.168.135.152"
[host."https://192.168.135.152"]
capabilities = ["pull","resolve","push"]
skip_verify = true
#重启containerd
systemctl restart containerd.service部署NFS动态供给持久化存储
#NFS服务端配置
#安装nfs-utils
yum install -y nfs-utils
#添加共享目录
vim /etc/exports
/data *(rw,sync,no_root_squash)
#启动nfs-utils
systemctl enable nfs-server.service --now
systemctl restart rpcbind.service
#检查
showmount -e
Export list for node01.example.com:
/data *
#需要安装nfs-utils,否则无法创建出PV(在每个节点都安装nfs-utils)
vim auto.yaml
apiVersion: v1
kind: ServiceAccount
metadata:
name: nfs-client-provisioner
# replace with namespace where provisioner is deployed
namespace: default
---
kind: ClusterRole
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: nfs-client-provisioner-runner
rules:
- apiGroups: [""]
resources: ["endpoints"]
verbs: ["get", "list", "watch", "create", "update", "patch"]
- apiGroups: [""]
resources: ["nodes"]
verbs: ["get", "list", "watch"]
- apiGroups: [""]
resources: ["persistentvolumes"]
verbs: ["get", "list", "watch", "create", "delete"]
- apiGroups: [""]
resources: ["persistentvolumeclaims"]
verbs: ["get", "list", "watch", "update"]
- apiGroups: ["storage.k8s.io"]
resources: ["storageclasses"]
verbs: ["get", "list", "watch"]
- apiGroups: [""]
resources: ["events"]
verbs: ["create", "update", "patch"]
---
kind: ClusterRoleBinding
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: run-nfs-client-provisioner
subjects:
- kind: ServiceAccount
name: nfs-client-provisioner
# replace with namespace where provisioner is deployed
namespace: default
roleRef:
kind: ClusterRole
name: nfs-client-provisioner-runner
apiGroup: rbac.authorization.k8s.io
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: nfs-client-provisioner
labels:
app: nfs-client-provisioner
# replace with namespace where provisioner is deployed
namespace: default
spec:
replicas: 1
strategy:
type: Recreate
selector:
matchLabels:
app: nfs-client-provisioner
template:
metadata:
labels:
app: nfs-client-provisioner
spec:
serviceAccountName: nfs-client-provisioner
containers:
- name: nfs-client-provisioner
image: registry.k8s.io/sig-storage/nfs-subdir-external-provisioner:v4.0.2
volumeMounts:
- name: nfs-client-root
mountPath: /persistentvolumes
env:
- name: PROVISIONER_NAME
value: k8s-sigs.io/nfs-subdir-external-provisioner
- name: NFS_SERVER
value: 192.168.135.154
- name: NFS_PATH
value: /data
volumes:
- name: nfs-client-root
nfs:
server: 192.168.135.154
path: /data
#创建SC
vim sc.yaml
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: nfs-client
provisioner: k8s-sigs.io/nfs-subdir-external-provisioner # 动态供给:由上面的控制器处理
parameters:
pathPattern: "${.PVC.namespace}/${.PVC.name}" # 每个 PVC 一个独立子目录
onDelete: delete # PVC 删除时删除子目录
reclaimPolicy: Delete # 由 SC 决定回收策略
volumeBindingMode: Immediate
mountOptions:
- vers=4.1
#创建PVC测试
vim pvc.yaml
kind: PersistentVolumeClaim
apiVersion: v1
metadata:
name: nfs-pvc
spec:
storageClassName: nfs-client
accessModes:
- ReadWriteMany
resources:
requests:
storage: 200Mi部署Jenkins
#拉取部署的yaml文件
git clone https://github.com/scriptcamp/kubernetes-jenkins
#修改volume.yaml持久化存储的yaml文件
#修改deployment调度节点
#执行yaml文件
kubectl apply -f /root/kubernetes-jenkins #执行kubernetes-jenkins目录下所有yaml文件
#查询密码
kubectl logs -n devops-tools jenkins-6846f7864d-fpdbb部署ingress nginx
#拉取ingress-nginx
wget https://raw.githubusercontent.com/kubernetes/ingress-nginx/controller-v1.14.0/deploy/static/provider/baremetal/deploy.yaml
#执行
kubectl apply -f deploy.yaml
#设置nginx ingress为默认的ingress控制器
#查询集群中所有的ingressclass
kubectl get ingressclasses.networking.k8s.io
kubectl edit ingressclasses.networking.k8s.io nginx
ingressclass.kubernetes.io/is-default-class: true #添加这行注解
作用:在配置ingress的规则时,不指定ingress的控制器,则采用默认的ingressjenkins
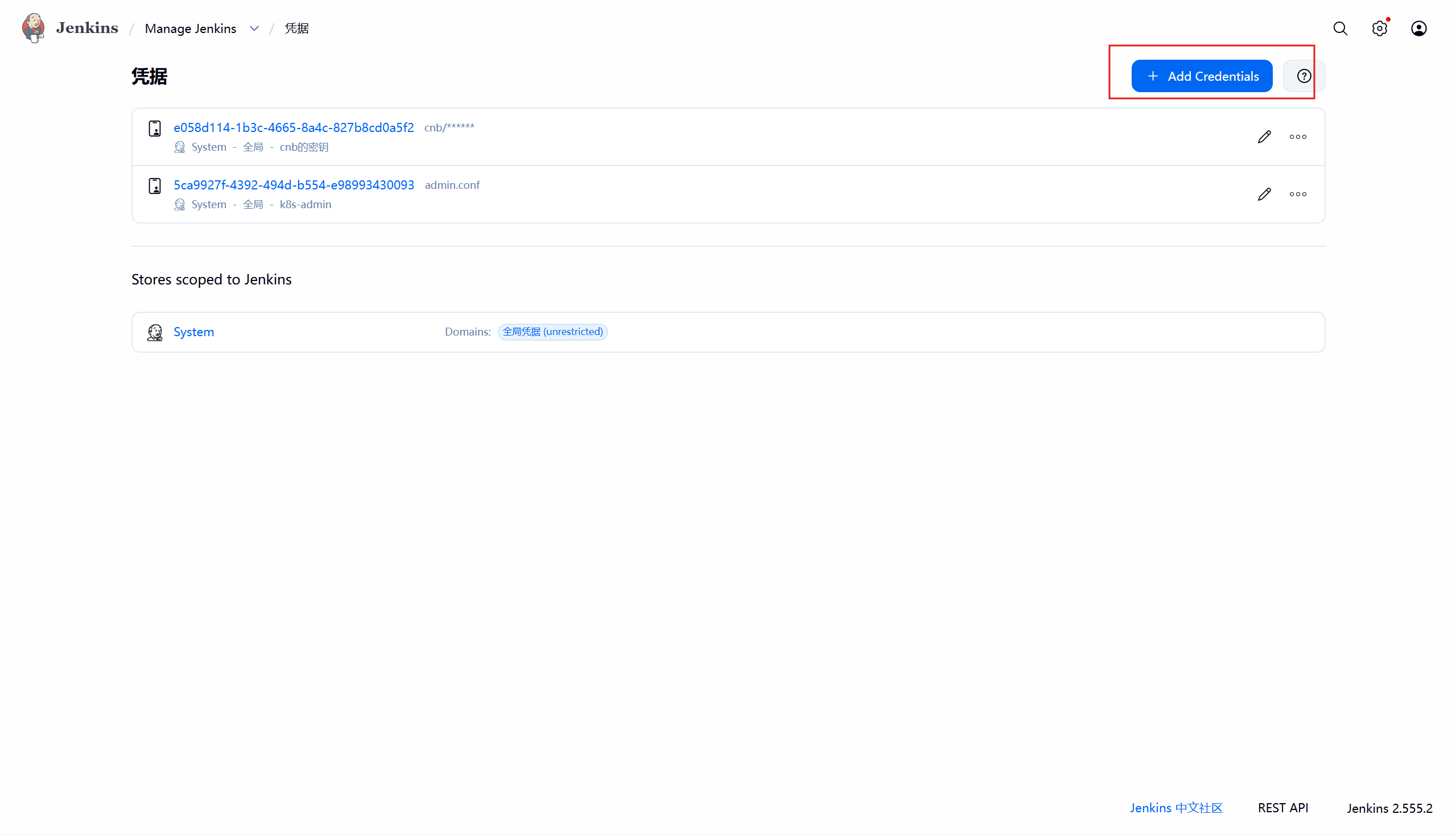
添加cnb代码仓库凭据
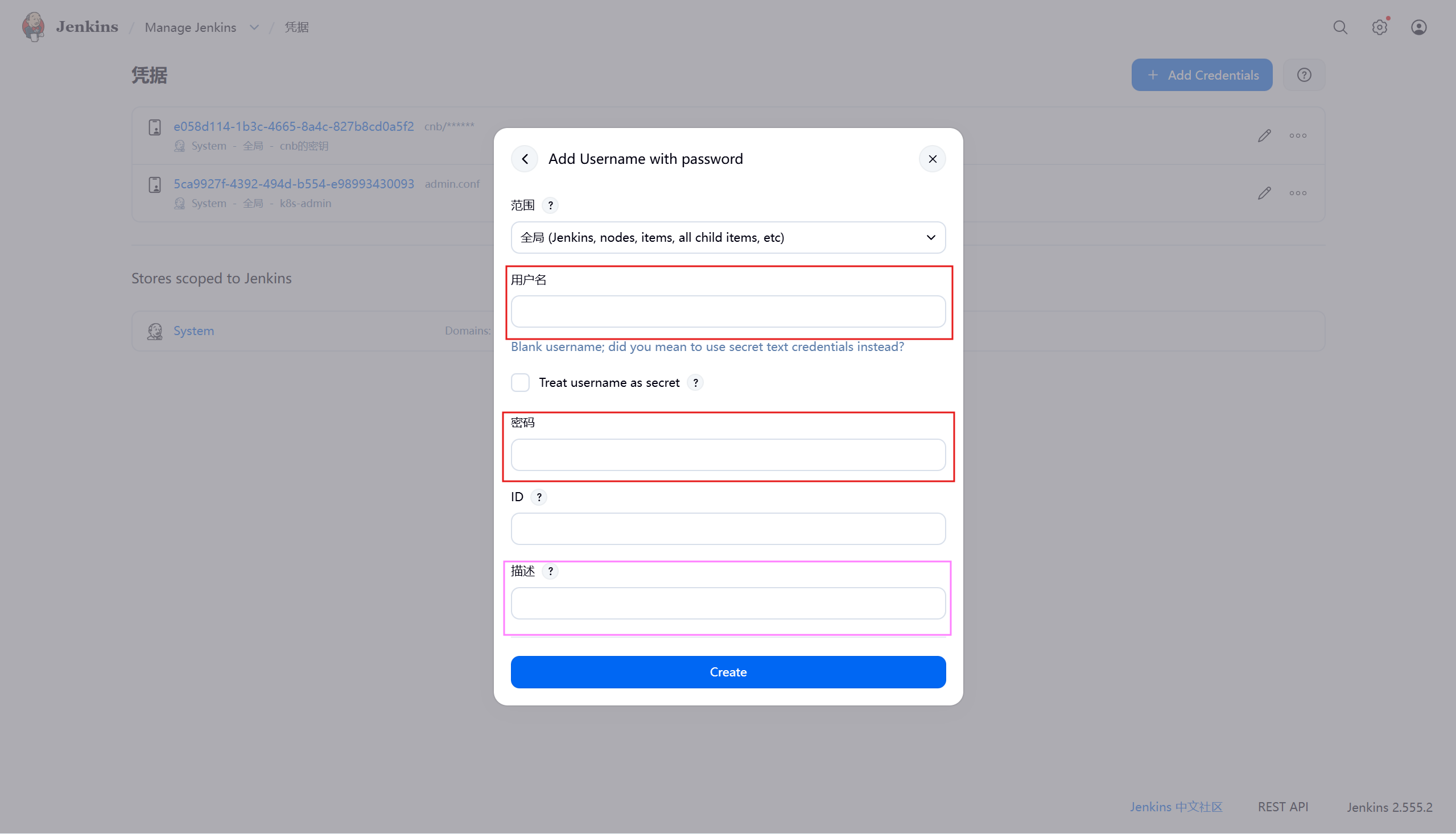
pipeline
pipeline {
agent {
kubernetes {
cloud 'kubernetes'
namespace 'halo-app'
yaml '''
apiVersion: v1
kind: Pod
spec:
containers:
- image: 192.168.135.152/talo/rocky9.6:tools
name: tools
command:
- /bin/bash
- -c
- sleep 99999
- image: 192.168.135.152/talo/docker-cli:latest
name: dockercli
command:
- /bin/bash
- -c
- sleep 99999
volumeMounts:
- name: kubectl
mountPath: /usr/bin/kubectl
readOnly: true
volumes:
- name: kubectl
hostPath:
path: /usr/bin/kubectl
type: File
'''
}
}
options {
timestamps()
disableConcurrentBuilds()
}
environment {
HARBOR_ADDR = '192.168.135.152'
HARBOR_USER = 'admin'
HARBOR_PASS = 'Harbor12345'
IMAGE_REPO = '192.168.135.152/app/talo-app'
DOCKER_HOST = 'tcp://192.168.135.152:2375'
KUBECONFIG = './admin.conf'
APP_NAMESPACE = 'halo'
}
stages {
stage('拉取代码') {
steps {
container('tools') {
git branch: 'main',
credentialsId: 'e058d114-1b3c-4665-8a4c-827b8cd0a5f2',
url: 'https://cnb.cool/gslinux/talo.git'
}
}
}
stage('编译项目') {
steps {
container('tools') {
sh '''
#因为原地址需要科学上网,所以拉取到本地并存放到apache中,加快编译的速度
sed -i 's#^distributionUrl=.*#distributionUrl=http\\://192.168.135.151/distributions/gradle-9.5.0-bin.zip#' gradle/wrapper/gradle-wrapper.properties
./gradlew clean build -x test -x spotlessCheck || \
./gradlew clean build -x test -x spotlessCheck
'''
}
}
}
stage('构建并推送镜像') {
steps {
container('dockercli') {
sh '''
cat > Dockerfile <<'EOF'
FROM 192.168.135.152/talo/eclipse-temurin:21-jre AS builder
WORKDIR /application
ARG JAR_FILE=/application/build/libs/*.jar
COPY ${JAR_FILE} application.jar
RUN java -Djarmode=tools -jar application.jar extract --layers --destination extracted
FROM 192.168.135.152/talo/eclipse-temurin:21-jre
LABEL maintainer="johnniang <johnniang@foxmail.com>"
WORKDIR /application
COPY --from=builder /application/extracted/dependencies/ ./
COPY --from=builder /application/extracted/spring-boot-loader/ ./
COPY --from=builder /application/extracted/snapshot-dependencies/ ./
COPY --from=builder /application/extracted/application/ ./
ENV JVM_OPTS="" \
HALO_WORK_DIR="/root/.halo2" \
SPRING_CONFIG_LOCATION="optional:classpath:/;optional:file:/root/.halo2/" \
TZ=Asia/Shanghai
RUN ln -sf /usr/share/zoneinfo/$TZ /etc/localtime \
&& echo $TZ > /etc/timezone
RUN java -XX:ArchiveClassesAtExit=application.jsa \
-Dspring.context.exit=onRefresh \
-jar application.jar \
--halo.work-dir=/tmp/halo2 \
&& rm -rf /tmp/halo2
EXPOSE 8090
ENTRYPOINT ["sh", "-c", "exec java ${JVM_OPTS} -XX:SharedArchiveFile=application.jsa -jar application.jar \\"$@\\"", "--"]
EOF
docker login -u "${HARBOR_USER}" -p "${HARBOR_PASS}" "${HARBOR_ADDR}"
docker build -t "${IMAGE_REPO}:v${BUILD_NUMBER}" .
docker push "${IMAGE_REPO}:v${BUILD_NUMBER}"
'''
}
}
}
stage('部署到 Kubernetes') {
steps {
container('dockercli') {
sh '''
cat > admin.conf <<EOF
apiVersion: v1
clusters:
- cluster:
certificate-authority-data: LS0tLS1CRUdJTiBDRVJUSUZJQ0FURS0tLS0tCk1JSURCVENDQWUyZ0F3SUJBZ0lJRUU2OFdiMXZWd2d3RFFZSktvWklodmNOQVFFTEJRQXdGVEVUTUJFR0ExVUUKQXhNS2EzVmlaWEp1WlhSbGN6QWVGdzB5TlRFeE1qTXhNVFF6TkRaYUZ3MHpOVEV4TWpFeE1UUTRORFphTUJVeApFekFSQmdOVkJBTVRDbXQxWW1WeWJtVjBaWE13Z2dFaU1BMEdDU3FHU0liM0RRRUJBUVVBQTRJQkR3QXdnZ0VLCkFvSUJBUURaMzF6Qi8xcnp3S21UalBrOFlBS0FYd1pwMStUS2R6cGhUVW5UUjZuWjhYbWRQcjBjVjNUaERyR0YKNFcrYSs1MnpNS0lNbDJoalNFRmNkRndSOFE0NDR1YTE0YU5GTmJxRDFhUU91Rm1hWWM3U1hYZ0d5YXhuRGJOTQozY1lOZlpKSy94TXI0TEllN1JTT2d3TkRjSEkxMWJVNFhoeDFJekpUUmNUWU11a1VoaGFyTVd0TnRUSFdKNmc4CitlbHNmcDFiN1dFUW96bjcwbCtkVytWM2JaMkpDWmNKMm85MDhycVhLR1FBTjdpWXZCdnZUM1JUVlhOejdHbFcKUDdlbmxFNUQwT1Y5Nmp1clZobzNHKzNNNmZTMUZ0Kzh6LzVwZlZKQ0Q3VEpqd29pMmVvdkN0NHp2Szc4b1gydwprcTdpa3YxelZ1ZGpYUkZJNFZRb3dLS29oV1M3QWdNQkFBR2pXVEJYTUE0R0ExVWREd0VCL3dRRUF3SUNwREFQCkJnTlZIUk1CQWY4RUJUQURBUUgvTUIwR0ExVWREZ1FXQkJSQUdwTFJoNVpIemQvMVV5QVBjcGVkbndET2xUQVYKQmdOVkhSRUVEakFNZ2dwcmRXSmxjbTVsZEdWek1BMEdDU3FHU0liM0RRRUJDd1VBQTRJQkFRQXFEbXM1M29zRgpxS21Cbmc5WUlCYklPbEtzTG40MkpzZC9aVHl2YlI4bmJTczRtWUdpQ0I1cnhRNEUwcWtCdU80YjBFSHdFemtuCmVZd2NxSXhjZk9DQmRkeW9OK0J0NVVUejlPWjdLNnpkWUpFcERMckFITlg0bVIwMWFscldjblJ6R21XTDlPdUgKeWNpU0l5TWRsb1BCVkRNSDQ1QTFKWS8xa3grc0V0cFNrK21TMFpkNS9VTVVaaXI1ZU1WMWxXWlppYWJyZDhtVApuR0hvbUhMZnQvWi9jbHA2WGNDVWRrM05PZm90WEFPbkpSakROQWpxNWxQemMrNDM1TlB0ajZYRVRYbVhxM2FnCng3bWhJZ3VtKysyQ2pVWlRWckRPTFZBVTU4TE1Sb0pXczl1Y3drR00vcHYwK2VuMW1WWkZsclVYaEp6bWtQTEsKSU1vRE0wOUI4OTl5Ci0tLS0tRU5EIENFUlRJRklDQVRFLS0tLS0K
server: https://192.168.135.150:16443
name: kubernetes
contexts:
- context:
cluster: kubernetes
user: kubernetes-admin
name: kubernetes-admin@kubernetes
current-context: kubernetes-admin@kubernetes
kind: Config
preferences: {}
users:
- name: kubernetes-admin
user:
client-certificate-data: LS0tLS1CRUdJTiBDRVJUSUZJQ0FURS0tLS0tCk1JSURLVENDQWhHZ0F3SUJBZ0lJT1BsNENMY0hiSFV3RFFZSktvWklodmNOQVFFTEJRQXdGVEVUTUJFR0ExVUUKQXhNS2EzVmlaWEp1WlhSbGN6QWVGdzB5TlRFeE1qTXhNVFF6TkRaYUZ3MHlOakV4TWpNeE1UUTRORFphTUR3eApIekFkQmdOVkJBb1RGbXQxWW1WaFpHMDZZMngxYzNSbGNpMWhaRzFwYm5NeEdUQVhCZ05WQkFNVEVHdDFZbVZ5CmJtVjBaWE10WVdSdGFXNHdnZ0VpTUEwR0NTcUdTSWIzRFFFQkFRVUFBNElCRHdBd2dnRUtBb0lCQVFDbTdIbU4KcEF2eEw4VkJMbklsRmY5LzM1RjJvaHFacGg4a0F4WFAweStFRHFJMTBSUUFKbGZMd2ozOEY0aHpJUzdhbGNjQwpwUmlRWlcxVS95UkdCQUlFcEF2aXh6cWMxRjNmU0t4a1JTcjJzdkxoOHlXN2xrWU9uc3NvOVM3NThDRXRqdnBzCmhoUXF5WSs3V0JTOU5jNHdDTFNxbEM3d3RpYzRqajBMTkdINkZ2TFZhMWZ5aFlRNGdVVitlc21uNThnZEpZNWYKUkFiSm5KN1VwOTdGeGhwOHlmUVZuMVp6b0dMS1M3S3FnclpEdXlhbWdEQjJmVHMxTlNPN3VBZVFIb3l2NElJbwpwbXRCVmtLb2ZUaitQVlAzVXVxMllsZ1ZuQmFLSy9ZQ3VYREFxTWlLK3NEU1FNOHAxTjRYbUQ4ZVcra0lsSFVFCnZjN05kYlArTzRLTzZHQ1pBZ01CQUFHalZqQlVNQTRHQTFVZER3RUIvd1FFQXdJRm9EQVRCZ05WSFNVRUREQUsKQmdnckJnRUZCUWNEQWpBTUJnTlZIUk1CQWY4RUFqQUFNQjhHQTFVZEl3UVlNQmFBRkVBYWt0R0hsa2ZOMy9WVApJQTl5bDUyZkFNNlZNQTBHQ1NxR1NJYjNEUUVCQ3dVQUE0SUJBUUFydW1leWFCTDQ5SmJuN1pudjE2TkJOdFAwCjBObk1yR09zWnJyVlpQU3NZWjNMelUrTG4rL1ZtTXd1OE1XVUI0dnIvWXQwUlRRaHdQdGV0Zmk2c0szMTNCeXUKbWdtUCthQWxrR0VqSzA4aThDOXlPc3I4bmZrN0pMTm9CUEdUSC93MDl1cEpyTmVyTTlQVTc0SUlYek0zQklFRQpGSk5UOU9PU01sQnd0Qk04K0grSXhIVERuWFUzd2FlMWZlWmJQb1BPZXNIbFhJSTgzK1BMZWZyVGx2dksyS2FEClkzV2x1Z1MwWVVFYjlUZEN3RFRxS1dKWUxIbC9DQS9EWlZMZ0E5THFZaGU4a3FINTl5NTFnRlAyemE0SEs4cnQKNmFaTDNyY0xNaEVkdlc0Mkd5QzhYV3J5Yk5LREJlTWJXc3JBcDNzbmJnaEtIVGV2aWRMQlhMQVVyTE9iCi0tLS0tRU5EIENFUlRJRklDQVRFLS0tLS0K
client-key-data: LS0tLS1CRUdJTiBSU0EgUFJJVkFURSBLRVktLS0tLQpNSUlFcFFJQkFBS0NBUUVBcHV4NWphUUw4Uy9GUVM1eUpSWC9mOStSZHFJYW1hWWZKQU1WejlNdmhBNmlOZEVVCkFDWlh5OEk5L0JlSWN5RXUycFhIQXFVWWtHVnRWUDhrUmdRQ0JLUUw0c2M2bk5SZDMwaXNaRVVxOXJMeTRmTWwKdTVaR0RwN0xLUFV1K2ZBaExZNzZiSVlVS3NtUHUxZ1V2VFhPTUFpMHFwUXU4TFluT0k0OUN6UmgraGJ5MVd0WAo4b1dFT0lGRmZuckpwK2ZJSFNXT1gwUUd5WnllMUtmZXhjWWFmTW4wRlo5V2M2Qml5a3V5cW9LMlE3c21wb0F3CmRuMDdOVFVqdTdnSGtCNk1yK0NDS0taclFWWkNxSDA0L2oxVDkxTHF0bUpZRlp3V2lpdjJBcmx3d0tqSWl2ckEKMGtEUEtkVGVGNWcvSGx2cENKUjFCTDNPelhXei9qdUNqdWhnbVFJREFRQUJBb0lCQUFNOFRZcmZwWCtjL205LwpWL3BuWW13aHlFUmdGZ1hwRmhkdzhUT2dhS2tLK09mMEpUVnZpTlRMNzJtbDNIWThMQmYraytkSzQwbFdrMHowCnpuT0dVUWV5cWxiN1VrNkhRSjZRWG1ScDF0QmJYYUUxbGxpbTFyVjMxeXVmRWw4Sk51REJoeEhOYzRkS0lEMXcKWi9rc1JDZmkzZnI1emxoMHloa3E0S2Rlbk9ZOUV2VDllcE80N1JERGd3b3VnanVIdTJkT3YvNlBGRGtaNStkVgo2YnBRN1kyT2FtN2owUHdCLzk3d3R6TlN1QkNHT3Fnb01CRitjOW45ZjMxSHdjYmdYOGhIWXVVRnAvc3dicFY3Ci9USnVGdlhxOGdsT0hwTExBRzEwZXgvS3NOVDI1dUJHQ2xZWjVvRW5EbEVDd2t5WWFzbmNQM2VDRVpHcDFDQXoKTFRZYmx4RUNnWUVBeloxcGFadlp5ZitPWUtuSkRGcGdrSkhzSnpmd0p3LzJIZ29KU0U2U2tlY0lNRnRTOGZUQQphSVNienVhdHVmNG5wMC9uNE1NaUJYU1VTa3lXMXVaSStNYXYzeFdFRGY5V3YzWTBRQTVidjVGZ2V3SkpJMERrCko3R3o5eUhkZFJDQ1A4ODZWMWNrVGxUTkFnYWFNbVBYSEZsdGgxRlNIeXBoNWtBa2hTUTlLTFVDZ1lFQXo5UGwKemg4bW9hSFRTMlpySDVJTmd0Wit6TXJ5MmZxbUdWeXhVUWRiM1VMTnFBN0F3MkYwdWFtNXF6SlpjUW5Nb0Q0cwp5WjVMQk1LMUd6MzUwSXRPajBkVmV3WWdOc3hjUWg4b3l3bzVCMVRXS2xSWUd3M0VoR3JLeFlZbEFvckp6SXN6Cm9IZkZxTnR2QXZKWWlhcjkxanZ3L1RNMlJHb0lvTXdpcVpmcXV0VUNnWUVBa0g0SlFPMEQvTDc1YUJhSXNZU2wKalpMdU9KVkh6N3VZd24xZERwSWcwQ1ZpRE5Gd2xaWGd6Tkk3eUFjMW1KbnhkZE5pYVFIWDI2dVVOaTVpWmZ5SQoxVUtTL3h0WXBKbUdkWi8wa2Z0RklIZGlMSzlyaERtcTIvWTJPUHAwYlRxL3ZXVzhZdnBiQ2l6dnNIZkJUcDM0CjRmUTZVemlqbEVFdGNTZ3NRZUE0bG0wQ2dZRUFqalEwZTB4dlY0dHVFNXFaMC9sUXkyVFBVSHZSbmZ0V3FlWDEKNGpiQjBlMEM0V3B1MVlHYXArdU5ncW1wNzZHLzVTbUY1ZE10QzYzYTFEQWMvbWhEc2VBaWlsSlB1bzhzMVlXUwptUk4rb0JpWmprODJGaFRla2FpczVHajhhL2ZoU3RjNDFTVC9GNkpHSEdNTTErNHJUK3FsNCtxbHlEd3hlUzBVCnpxeUhUWjBDZ1lFQWgrdWF3WmFoWDRVbll4QWFZNERTYUxKL3hjWDRpWEV3S2JSNVorQ1BpQ0NGaDlNL3dPbDcKbUFrWU16Q1ZTbWxJQi9zMUhlOVRUVGtmMWt4ZzZPVE9DdjNyak13bUtFL1RDa2RENnovdkE1K0xYemNlMHp6WQo5Q0R1Z04rSnBzVFFrdUl0NDdaazFnbVpsUnN5c3VqU2VQNUI5RURVeXJGU1VxdHFQRUtHSWJVPQotLS0tLUVORCBSU0EgUFJJVkFURSBLRVktLS0tLQo=
EOF
cat > namespace.yaml <<EOF
apiVersion: v1
kind: Namespace
metadata:
name: ${APP_NAMESPACE}
EOF
kubectl --kubeconfig "${KUBECONFIG}" apply -f namespace.yaml
cat > all-halo.yaml <<EOF
kind: PersistentVolumeClaim
apiVersion: v1
metadata:
name: halo-pvc
namespace: ${APP_NAMESPACE}
spec:
storageClassName: nfs-client
accessModes:
- ReadWriteMany
resources:
requests:
storage: 5Gi
---
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
app: halo
name: halo
namespace: ${APP_NAMESPACE}
spec:
replicas: 1
selector:
matchLabels:
app: halo
template:
metadata:
labels:
app: halo
spec:
imagePullSecrets:
- name: harbor-secret
containers:
- image: ${IMAGE_REPO}:v${BUILD_NUMBER}
imagePullPolicy: IfNotPresent
name: halo
ports:
- name: http
containerPort: 8090
args:
- --spring.r2dbc.url=r2dbc:pool:mysql://192.168.135.155:3306/halo
- --spring.r2dbc.username=root
- --spring.r2dbc.password=zgs888
- --spring.sql.init.platform=mysql
- --halo.external-url=http://www.zgs.com/
env:
- name: JVM_OPTS
value: "-Xmx256m -Xms256m"
resources:
requests:
cpu: 200m
memory: 512Mi
limits:
cpu: 1000m
memory: 1Gi
readinessProbe:
httpGet:
path: /actuator/health/readiness
port: 8090
initialDelaySeconds: 30
periodSeconds: 30
timeoutSeconds: 5
failureThreshold: 5
livenessProbe:
httpGet:
path: /actuator/health/liveness
port: 8090
initialDelaySeconds: 60
periodSeconds: 30
timeoutSeconds: 5
failureThreshold: 5
volumeMounts:
- name: halo
mountPath: /root/.halo2
volumes:
- name: halo
persistentVolumeClaim:
claimName: halo-pvc
---
apiVersion: v1
kind: Service
metadata:
labels:
app: halo-svc
name: halo-svc
namespace: ${APP_NAMESPACE}
spec:
ports:
- name: http
port: 8090
protocol: TCP
targetPort: 8090
selector:
app: halo
type: ClusterIP
---
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: halo-ingress
namespace: ${APP_NAMESPACE}
spec:
ingressClassName: nginx
rules:
- host: www.zgs.com
http:
paths:
- path: /
pathType: Prefix
backend:
service:
name: halo-svc
port:
number: 8090
---
apiVersion: autoscaling/v2
kind: HorizontalPodAutoscaler
metadata:
name: halo-hpa
namespace: ${APP_NAMESPACE}
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: halo
minReplicas: 1
maxReplicas: 1
metrics:
- type: Resource
resource:
name: cpu
target:
type: Utilization
averageUtilization: 70
- type: Resource
resource:
name: memory
target:
type: Utilization
averageUtilization: 80
behavior:
scaleUp:
stabilizationWindowSeconds: 0
selectPolicy: Max
policies:
- type: Pods
value: 1
periodSeconds: 30
- type: Percent
value: 100
periodSeconds: 60
scaleDown:
stabilizationWindowSeconds: 300
selectPolicy: Min
policies:
- type: Pods
value: 1
periodSeconds: 120
- type: Percent
value: 25
periodSeconds: 120
EOF
kubectl --kubeconfig "${KUBECONFIG}" apply -f all-halo.yaml
kubectl --kubeconfig "${KUBECONFIG}" -n "${APP_NAMESPACE}" rollout status deployment/halo --timeout=300s
'''
}
}
}
stage('查看部署结果') {
steps {
container('dockercli') {
sh '''
kubectl --kubeconfig "${KUBECONFIG}" -n "${APP_NAMESPACE}" get pod -o wide
kubectl --kubeconfig "${KUBECONFIG}" -n "${APP_NAMESPACE}" get svc
kubectl --kubeconfig "${KUBECONFIG}" -n "${APP_NAMESPACE}" get ingress
kubectl --kubeconfig "${KUBECONFIG}" -n "${APP_NAMESPACE}" get hpa
'''
}
}
}
}
post {
success {
echo '流水线执行成功,Halo 已部署到 Kubernetes。'
}
failure {
echo '流水线执行失败,请检查 Jenkins 控制台日志。'
}
}
}
#在jenkins中创建流水线,然后将pipeline贴进去即可prometheus
这种安装方式内置了grafana的可视化仪表盘,部署完成通过已有的可视化仪表盘,通过命名空间即可对Pod进行监控,如果需要监控应用本身的指标,则需要应用暴露/metric指标采集
安装helm
kubectl get nodes
kubectl get ns
helm version
#如果没有则安装,去官网下载安装添加Prometheus的helm仓库
helm repo add prometheus-community https://prometheus-community.github.io/helm-charts
helm repo update查看 Chart
helm search repo prometheus-community/kube-prometheus-stack官方社区 Chart 仓库在 prometheus-community/helm-charts下维护
创建命名空间
kubectl create namespace monitoring准备 values.yaml
vim values.yaml
grafana:
enabled: true
adminUser: admin
adminPassword: "Admin@123456"
service:
type: NodePort
nodePort: 30300
persistence:
enabled: true
type: pvc
storageClassName: "nfs-client"
accessModes:
- ReadWriteOnce
size: 5Gi
prometheus:
service:
type: NodePort
nodePort: 30090
prometheusSpec:
retention: 15d
serviceMonitorSelectorNilUsesHelmValues: false
podMonitorSelectorNilUsesHelmValues: false
ruleSelectorNilUsesHelmValues: false
storageSpec:
volumeClaimTemplate:
spec:
storageClassName: "nfs-client"
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 20Gi
alertmanager:
enabled: true
service:
type: NodePort
nodePort: 30903
alertmanagerSpec:
storage:
volumeClaimTemplate:
spec:
storageClassName: "nfs-client"
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 5Gi注意:这里的 storageClassName: "nfs-client" 要改成你自己集群里的 StorageClass。
如何创建NFS动态供给的StorageClass可以参考#################
查看你的 StorageClass
kubectl get storageclass如果你没有 StorageClass,可以先把 storageSpec和 persistence相关配置删掉,先用非持久化方式跑起来。
安装 Prometheus
helm upgrade --install prometheus prometheus-community/kube-prometheus-stack \
-n monitoring \
-f values.yaml
#等待Pod启动
kubectl get pods -n monitoring -w
#看到如下状态则正常
prometheus-grafana-xxx Running
prometheus-kube-prometheus-operator-xxx Running
prometheus-kube-state-metrics-xxx Running
prometheus-prometheus-node-exporter-xxx Running
prometheus-kube-prometheus-prometheus-0 Running
alertmanager-prometheus-kube-prometheus-alertmanager-0 Running
#查看SVC
kubectl get svc -n monitoring
#查看SVC暴露的端口,通过浏览器去访问Prometheus和Grafana注意事项
部署之后,prometheus对于一些指标抓取不到,因为kubernetes中的组件默认监听127.0.0.1,需要手动修改配置使其监听指定地址或者0.0.0.0,prometheus才能抓取到指标
!!!!!!!!!!每台master都需要改,改完之后不需要做任何操作,因为静态Pod会自动重新负载!!!!!!!!!!
kube-controller-manager
vi /etc/kubernetes/manifests/kube-controller-manager.yaml
- --bind-address=127.0.0.1
#修改为下面的
- --bind-address=0.0.0.0kube-etcd
vi /etc/kubernetes/manifests/etcd.yaml
- --listen-metrics-urls=http://127.0.0.1:2381
#修改为
- --listen-metrics-urls=http://0.0.0.0:2381kube-scheduler
vi /etc/kubernetes/manifests/kube-scheduler.yaml
- --bind-address=127.0.0.1
#修改为
- --bind-address=0.0.0.0kube-proxy
kubectl -n kube-system edit cm kube-proxy
metricsBindAddress: 127.0.0.1:10249
#修改为
metricsBindAddress: 0.0.0.0:10249
#这个需要手动重载
kubectl -n kube-system rollout restart ds kube-proxy修改完成之后查看端口是否监听在指定IP地址
ss -antupl | grep -E '(2381|10257|10249|10259)'
配置告警通知
告警规则配置
#以钉钉作为告警媒介为例
#在钉钉创建账号,然后创建一个群聊,在群聊中添加自定义机器人,创建好之后复制token和secert(安全设置选择标签)
#创建告警规则文件
vim halo-alert-rules.yaml
apiVersion: monitoring.coreos.com/v1
kind: PrometheusRule
metadata:
name: halo-alert-rules
namespace: monitoring
labels:
release: prometheus #注意这里的标签,使用helm list -n monitoring查询CHART下方的就是标签
spec:
groups:
- name: halo.pod.resource.rules
rules:
- alert: HaloPodCpuUsageHigh
expr: |
(
sum by (namespace, pod) (
rate(container_cpu_usage_seconds_total{
namespace="halo",
container!="",
image!=""
}[5m])
)
/
sum by (namespace, pod) (
kube_pod_container_resource_limits{
namespace="halo",
resource="cpu",
unit="core"
}
)
) * 100 > 80
and
sum by (namespace, pod) (
kube_pod_container_resource_limits{
namespace="halo",
resource="cpu",
unit="core"
}
) > 0
for: 3m
labels:
severity: warning
namespace: halo
annotations:
summary: "Halo Pod CPU 使用率过高"
description: "Pod {{ $labels.namespace }}/{{ $labels.pod }} CPU 使用率超过 limit 的 80%,当前值:{{ $value }}%"
- alert: HaloPodMemoryUsageHigh
expr: |
(
sum by (namespace, pod) (
container_memory_working_set_bytes{
namespace="halo",
container!="",
image!=""
}
)
/
sum by (namespace, pod) (
kube_pod_container_resource_limits{
namespace="halo",
resource="memory",
unit="byte"
}
)
) * 100 > 80
and
sum by (namespace, pod) (
kube_pod_container_resource_limits{
namespace="halo",
resource="memory",
unit="byte"
}
) > 0
for: 3m
labels:
severity: warning
namespace: halo
annotations:
summary: "Halo Pod 内存使用率过高"
description: "Pod {{ $labels.namespace }}/{{ $labels.pod }} 内存使用率超过 limit 的 80%,当前值:{{ $value }}%"
- name: k8s.node.rules
rules:
- alert: K8sNodeNotReady
expr: |
kube_node_status_condition{
condition="Ready",
status="true"
} == 0
for: 3m
labels:
severity: critical
annotations:
summary: "K8s 节点 NotReady"
description: "节点 {{ $labels.node }} 已经超过 3 分钟处于 NotReady 状态"
- alert: NodeExporterDown
expr: |
up{job="node-exporter"} == 0
for: 3m
labels:
severity: critical
annotations:
summary: "Node Exporter 掉线"
description: "节点监控目标 {{ $labels.instance }} 已经超过 3 分钟无法被 Prometheus 抓取"
#应用规则文件
kubectl apply -f halo-alert-rules.yaml
#检查是否生效
kubectl get prometheusrule -n monitoring
#runing后去prometheus的web页面选择rule选项查看规则是否UP,如果是DOWN状态可以等几分钟告警媒介配置
#配置
vim prometheus-webhook-dingtalk.yaml
apiVersion: v1
kind: ConfigMap
metadata:
name: prometheus-webhook-dingtalk
namespace: monitoring
data:
config.yml: |
timeout: 5s
targets:
webhook1:
url: https://oapi.dingtalk.com/robot/send?access_token=你的钉钉机器人token #修改为自己的
secret: SEC你的钉钉加签secret #修改为自己的
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: prometheus-webhook-dingtalk
namespace: monitoring
spec:
replicas: 1
selector:
matchLabels:
app: prometheus-webhook-dingtalk
template:
metadata:
labels:
app: prometheus-webhook-dingtalk
spec:
containers:
- name: prometheus-webhook-dingtalk
image: timonwong/prometheus-webhook-dingtalk:v2.1.0
imagePullPolicy: IfNotPresent
args:
- --config.file=/etc/prometheus-webhook-dingtalk/config.yml
- --web.listen-address=:8060
ports:
- containerPort: 8060
name: http
volumeMounts:
- name: config
mountPath: /etc/prometheus-webhook-dingtalk
volumes:
- name: config
configMap:
name: prometheus-webhook-dingtalk
---
apiVersion: v1
kind: Service
metadata:
name: prometheus-webhook-dingtalk
namespace: monitoring
spec:
selector:
app: prometheus-webhook-dingtalk
ports:
- name: http
port: 8060
targetPort: 8060
#应用
kubectl apply -f prometheus-webhook-dingtalk.yaml
kubectl get pod -n monitoring | grep dingtalk
kubectl get svc -n monitoring | grep dingtalk
#测试钉钉webhook服务是否正常
kubectl run curl-test -n monitoring --rm -it --image=curlimages/curl -- sh
#进入容器后,执行以下测试命令(收到测试消息说明服务没问题)
curl -XPOST http://prometheus-webhook-dingtalk.monitoring.svc:8060/dingtalk/webhook1/send \
-H 'Content-Type: application/json' \
-d '{
"version": "4",
"groupKey": "test",
"status": "firing",
"receiver": "dingtalk",
"groupLabels": {"alertname": "测试告警"},
"commonLabels": {"alertname": "测试告警", "severity": "warning"},
"commonAnnotations": {"summary": "测试钉钉告警"},
"alerts": [
{
"status": "firing",
"labels": {"alertname": "测试告警", "severity": "warning"},
"annotations": {"summary": "测试钉钉告警", "description": "这是一条 Alertmanager 测试消息"}
}
]
}'
#修改helm的alertmanager配置
#导出当前helm的配置
helm get values prometheus -n monitoring > values.yaml
#编辑导出的配置(加入或者修改下面的配置),如果不知道怎么加入或修改,直接把导出的和下面的配置贴给AI
vim values.yaml
alertmanager:
config:
global:
resolve_timeout: 5m
route:
group_by: ['alertname', 'namespace', 'pod', 'node']
group_wait: 30s
group_interval: 5m
repeat_interval: 1h
receiver: 'dingtalk-default'
routes:
- receiver: 'null'
matchers:
- alertname = "Watchdog"
- receiver: 'dingtalk-critical'
matchers:
- severity = "critical"
repeat_interval: 10m
- receiver: 'dingtalk-warning'
matchers:
- severity = "warning"
repeat_interval: 30m
receivers:
- name: 'null'
- name: 'dingtalk-default'
webhook_configs:
- url: 'http://prometheus-webhook-dingtalk.monitoring.svc:8060/dingtalk/webhook1/send'
send_resolved: true
- name: 'dingtalk-critical'
webhook_configs:
- url: 'http://prometheus-webhook-dingtalk.monitoring.svc:8060/dingtalk/webhook1/send'
send_resolved: true
- name: 'dingtalk-warning'
webhook_configs:
- url: 'http://prometheus-webhook-dingtalk.monitoring.svc:8060/dingtalk/webhook1/send'
send_resolved: true
inhibit_rules:
- source_matchers:
- severity = "critical"
target_matchers:
- severity =~ "warning|info"
equal:
- namespace
- alertname
- source_matchers:
- severity = "warning"
target_matchers:
- severity = "info"
equal:
- namespace
- alertname
#更新helm
helm upgrade prometheus prometheus-community/kube-prometheus-stack \
-n monitoring \
-f values.yamlnginx+keepalived
nginx
vim /etc/nginx/nginx.conf
upstream ingress_nginx {
server 192.168.135.151:31051 max_fails=3 fail_timeout=10s;
server 192.168.135.152:31051 max_fails=3 fail_timeout=10s;
server 192.168.135.153:31051 max_fails=3 fail_timeout=10s;
server 192.168.135.154:31051 max_fails=3 fail_timeout=10s;
server 192.168.135.155:31051 max_fails=3 fail_timeout=10s;
}
server {
listen 80 default_server;
listen [::]:80 default_server;
server_name www.zgs.com;
root /usr/share/nginx/html;
# Load configuration files for the default server block.
include /etc/nginx/default.d/*.conf;
location / {
proxy_pass http://ingress_nginx;
proxy_http_version 1.1;
proxy_set_header Host www.zgs.com;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
proxy_set_header X-Forwarded-Proto $scheme;
proxy_set_header Upgrade $http_upgrade;
proxy_set_header Connection "upgrade";
}
error_page 404 /404.html;
location = /40x.html {
}
error_page 500 502 503 504 /50x.html;
location = /50x.html {
}
}keepalived
vim /etc/keepalived/keepalived.conf
global_defs {
router_id master01
script_user root
enable_script_security
}
vrrp_script chk_nginx {
script "/etc/keepalived/check_nginx.sh"
interval 2
weight -30
fall 3
rise 2
}
vrrp_instance VI_1 {
state MASTER #备节点改成BACKUP
interface ens160
virtual_router_id 51
priority 120 #备节点优先级设置为100
advert_int 1
authentication {
auth_type PASS
auth_pass zgs123
}
virtual_ipaddress {
192.168.135.100/24
}
track_script {
chk_nginx
}
}
#检测脚本
vim /etc/keepalived/check_nginx.sh
#!/bin/bash
pidof nginx > /dev/null 2>&1
if [ $? -eq 0 ]; then
exit 0
else
exit 1
fiMySQL
部署MySQL
搭建MGR集群
主节点
#修改配置文件
vim /etc/my.cnf
server_id=1 #id号要唯一
gtid_mode=ON
enforce_gtid_consistency=ON
master_info_repository=TABLE
relay_log_info_repository=TABLE
binlog_checksum=NONE
log_slave_updates=ON
log_bin=binlog
binlog_format=ROW
transaction_write_set_extraction=XXHASH64
loose-group_replication_group_name='ce9be252-2b71-11e6-b8f4-00212844f856'
loose-group_replication_start_on_boot=off
loose-group_replication_local_address='192.168.135.153:33061'
loose-group_replication_group_seeds='192.168.135.153:33061,192.168.135.154:33061,192.168.135.155:33061'
loose-group_replication_bootstrap_group=off
#创建同步用户,刷新权限
set sql_log_bin=0;
grant replication slave on *.* to repl@'192.168.135.%' identified by '123456';
flush privileges;
set sql_log_bin=1;
#使用CHANGE MASTER TO语句将server配置为在下次需要从其他成员恢复其状态时,使用group_replication_recovery复制通道的给定凭据。
#构建group replication集群
change master to master_user='slave',master_password='Yutian_2026' for channel 'group_replication_recovery';
#安装group replication插件
set sql_log_bin=0;
grant replication slave on *.* to repl@'192.168.1.%' ident
#行初始引导操作,启动服务器192.168.135.153上mysql的group replication
set global group_replication_bootstrap_group=on;
#启动mgr集群
start group_replication;
set global group_replication_bootstrap_group=OFF;
#查看MGR状态
select * from performance_schema.replication_group_members;从节点
#修改配置文件
vim /etc/my.cnf
server_id=1 #id号要唯一
gtid_mode=ON
enforce_gtid_consistency=ON
master_info_repository=TABLE
relay_log_info_repository=TABLE
binlog_checksum=NONE
log_slave_updates=ON
log_bin=binlog
binlog_format=ROW
transaction_write_set_extraction=XXHASH64
loose-group_replication_group_name='ce9be252-2b71-11e6-b8f4-00212844f856'
loose-group_replication_start_on_boot=off
loose-group_replication_local_address='192.168.135.154:33061' #把这里改成所在节点的IP
loose-group_replication_group_seeds='192.168.135.153:33061,192.168.135.154:33061,192.168.135.155:33061'
loose-group_replication_bootstrap_group=off
#创建同步用户,刷新权限
set sql_log_bin=0;
grant replication slave on *.* to repl@'172.17.10.%' identified by '123456';
flush privileges;
set sql_log_bin=1;
#构建group replication集群
change master to master_user='repl',master_password='Yutian_2025' for channel 'group_replication_recovery';
#安装group replication插件
install plugin group_replication soname 'group_replication.so';
#把实例添加到之前的复制组
set global group_replication_allow_local_disjoint_gtids_join=ON;
start group_replication;
#查看复制组状态
select * from performance_schema.replication_group_members;
#单主模式下,查看主节点
select b.member_host the_master,a.variable_value master_uuid
from performance_schema.global_status a
join performance_schema.replication_group_members b
on a.variable_value = b.member_id
where variable_name='group_replication_primary_member';